株式会社Digeon
〒650-0035
兵庫県神戸市中央区浪花町64 三宮電電ビル 5階
〒650-0035
兵庫県神戸市中央区浪花町64 三宮電電ビル 5階
©株式会社Digeon All Rights Reserved.


目次
2025年8月14日、Googleが公開しているオープンソースなLLMシリーズ Gemma から、 「Gemma 3 270M」がリリース されました。
本記事ではそんな Gemma 3 270M について解説しながら、 LM Studio を用いて実際にこのモデルを手元のPCで動かすチュートリアルまで実施します。
手元のPCでローカルLLMを動かす方法については、「Ollama vs LM Studio ローカルLLMツールの特徴・使いやすさ・選び方ガイド」をご覧ください。
このモデルはその名の通り270M、つまり2.7億個のパラメータを持つ非常にコンパクトなモデルです。先日リリース されたOpenAI社のオープンウェイトモデルが gpt-oss-20b と gpt-oss-120b で、ぞれぞれ200億個、1,200億個のパラメータを有することから比較しても、その軽量さが分かります。
GPT-OSS については以下の記事で詳しく解説しています。
OpenAI GPT-OSS の実力を検証:高精度オープンLLMをローカル環境で安全・高速に活用する方法とは?【LM Studio】
Gemma 3 270M の特徴としては、2.7億個のパラメータのうち、1.7億個をトークンの埋め込みに必要なパラメータとしており、残りを Transformer ブロックとしている点です。
これによって膨大な語彙である25.6万個のトークンを扱うことができ、十分なパフォーマンスを発揮できるように構築されています。
そしてこれをベースに、特定ドメインや言語に合わせてファインチューニングすることで、その性能をさらに引き出す優れたベースモデルになっていると発表しています。
Gemma 3 270M はその軽量さとパフォーマンスから、電力消費が非常に小さいことが特徴として挙げられています。
Pixel 9 Pro によるテストでは、INT4で量子化されたモデルで25回のチャットの会話を行ったところ、わずか0.75%のバッテリー消費に留まり、 Gemmaシリーズの中で最も電力消費に優れたモデルであることが分かっています。
今回はベースモデルから指示追従性能を高めたモデルが別途公開されています。
このモデル自体は一般的な複雑な会話には必ずしも最適化されていないものの、指示追従において利用できる優れたモデルであると公表しています。
Gemma 3 270M は量子化を考慮した学習を行ったモデルを公開しています。
これによりパフォーマンスの低下を最小限にとどめながら、INT4で量子化された軽量・高速なモデルを動かすことができます。
このように優れた軽量化技術により、エッジデバイスでも高速に動作する Gemma 3 270M ですが、公式リリースにはその用途についても言及されています。
Googleのブログでは以下のようなケースに言及されています。
軽量・高速なモデルであるということは、汎用的な精度では大規模なモデルには及ばないという点は否めません。一方で大規模なモデルに大量のコンテキストを含めてさらに大量のタスクを解かせることは容易ではありません。
そのため、毎日や毎週などの頻度で非常に大量のデータを捌く必要があるような特定のタスクには、この Gemma 3 270M が適していると言えるでしょう。
例えばAIエージェントがタスクを実行するとき、通常数秒〜数分、長くて数十分の処理時間がかかることが多くあります。
ユーザーを数秒以上待たせることによって、システム利用の体験を損なうようなケースでは、この Gemma 3 270M が適していると言及しています。
例えば、先日の OpenAI GPT-5 のリリースでは、ユーザーのクエリを、
の2つのモデルのどちらで処理するべきかを切り替える機能があります。
このような処理の場合はなるべく高速にモデルを切り替える処理を挟み、早急にモデルにリクエストを転送する必要があります。このような例でこのモデルが適しているということです。
GPT-5の特徴に関する記事はこちらをご覧ください。
また他のユースケースとして、デバイス上で動作する Gemma 3 270M は、通信を必要とせずに、ユーザーのプライバシーを保護しながら利用できるLLMであるということで、データ漏洩防止などの用途でも利用できます。
ひとつのLLMをファインチューニングするには大量のデータと予算が必要になるため、ファインチューニングしたモデルを複数個用意して運用するのは容易ではありません。
一方で Gemma 3 270M は軽量で学習自体も比較的少ないリソースでできるため、特定の業務やドメインに特化した専門家としてのLLMをいくつも用意することが可能になりました。
今回はこの Gemma 3 270M を手元の MacbookPro で動かして、その速度と性能について確認していきます。
まずは LM Studio を ダウンロードページ からダウンロードして、インストールしてください。
LM Studio についての解説とそのセットアップ方法については、「LM Studioの使い方完全ガイド|ローカルPCでGPT-OSSを安全に動かす方法と特徴」を参照してください。
LM Studio の Gemma 3 270M は LM Studio のモデル一覧 に公開されていますので、こちらの「Use model in LM Studio」から動かすことができます。
このボタンを押下すると、 LM Studio のアプリ上で以下の画面が表示されるため、「Download」ボタンを押下し、モデルをダウンロードします。
ダウンロードが完了すると以下の画面になり、「Use in New Chat」から ChatGPT のような会話画面を起動します。
やはり270Mの軽量モデルですので、いわゆる ChatGPT や Gemini のような会話性能を期待することは難しいという課題があります。
今回は Google ブログでも言及されているような、特定の簡単なタスクレベルの会話をしていきます。
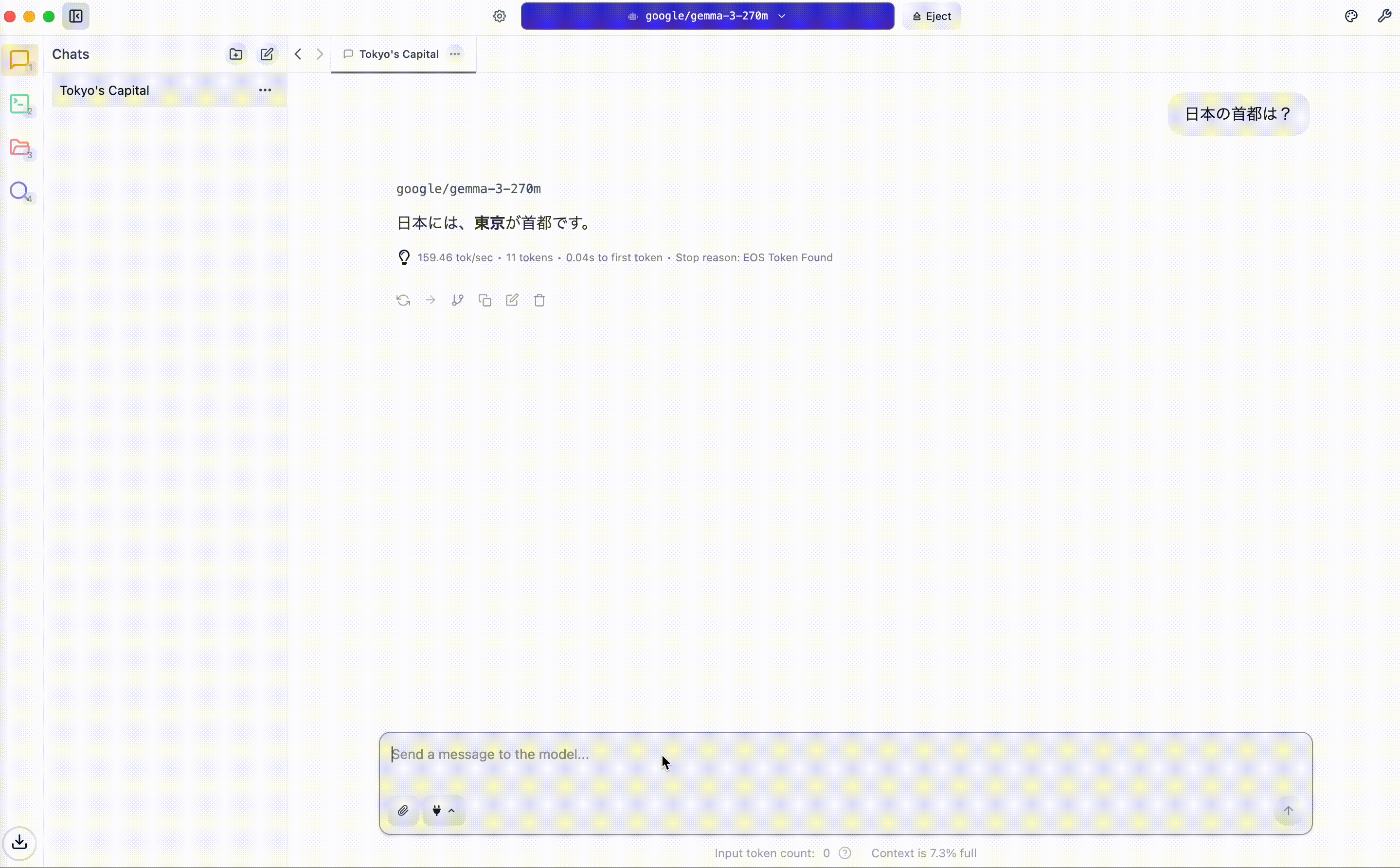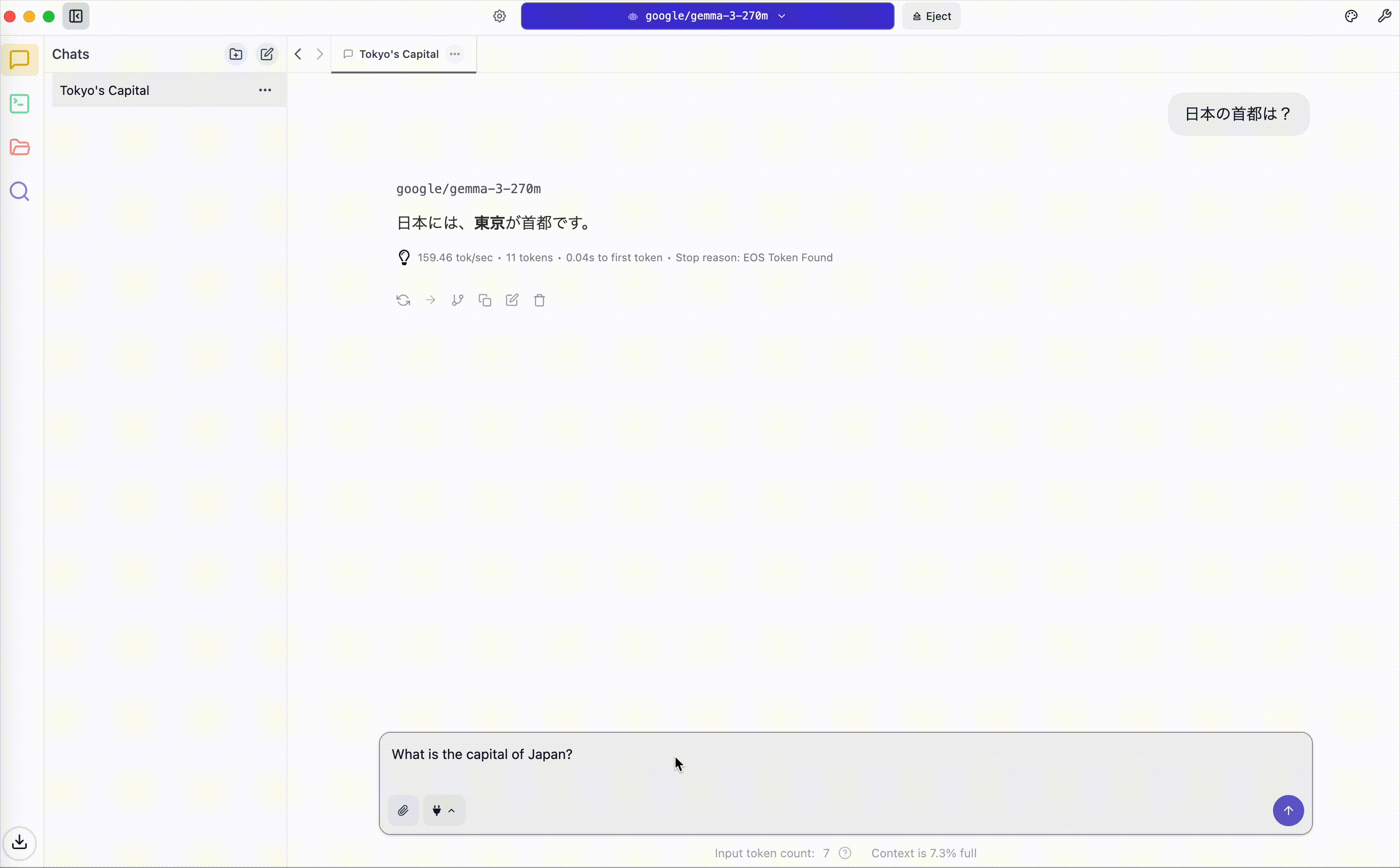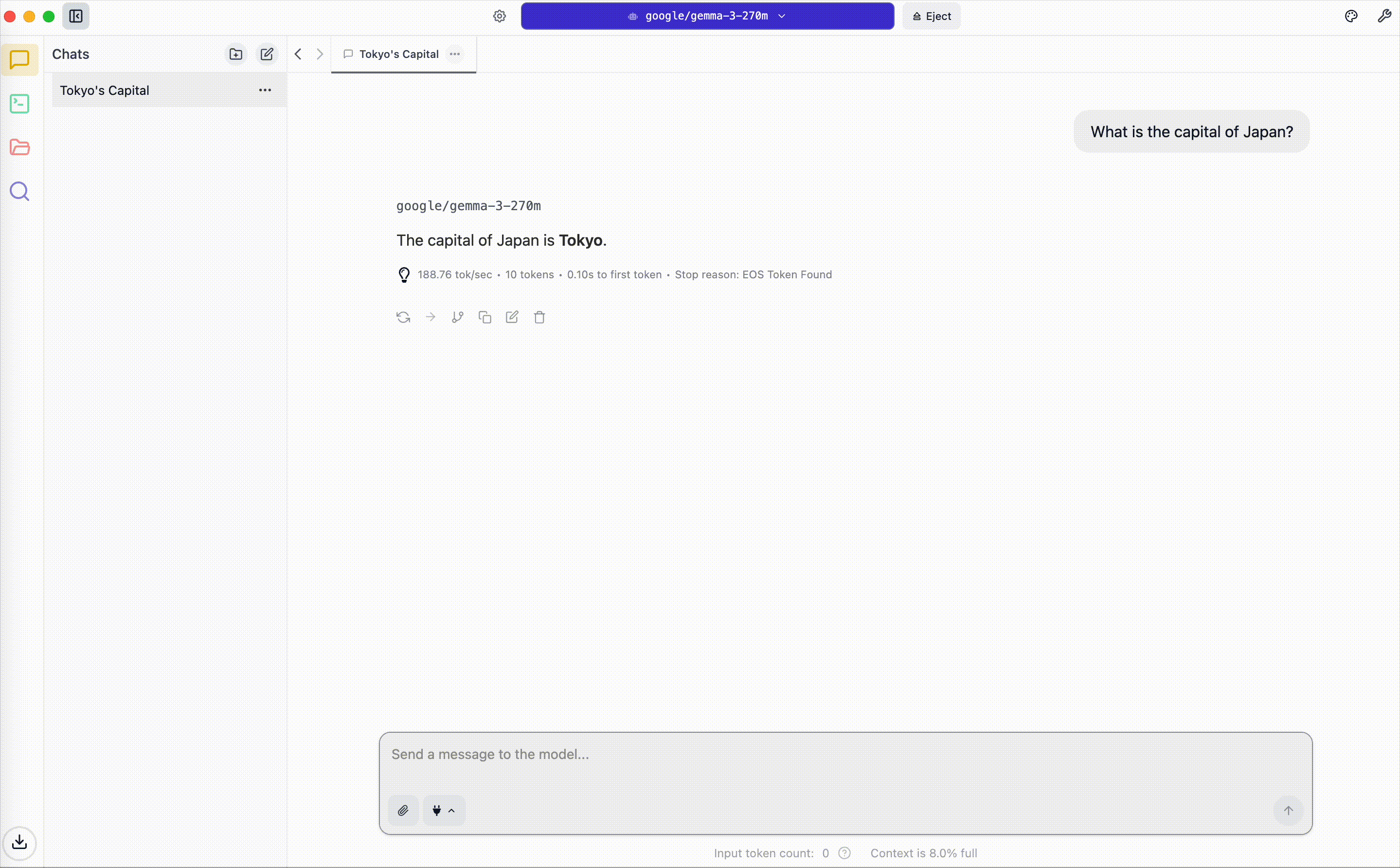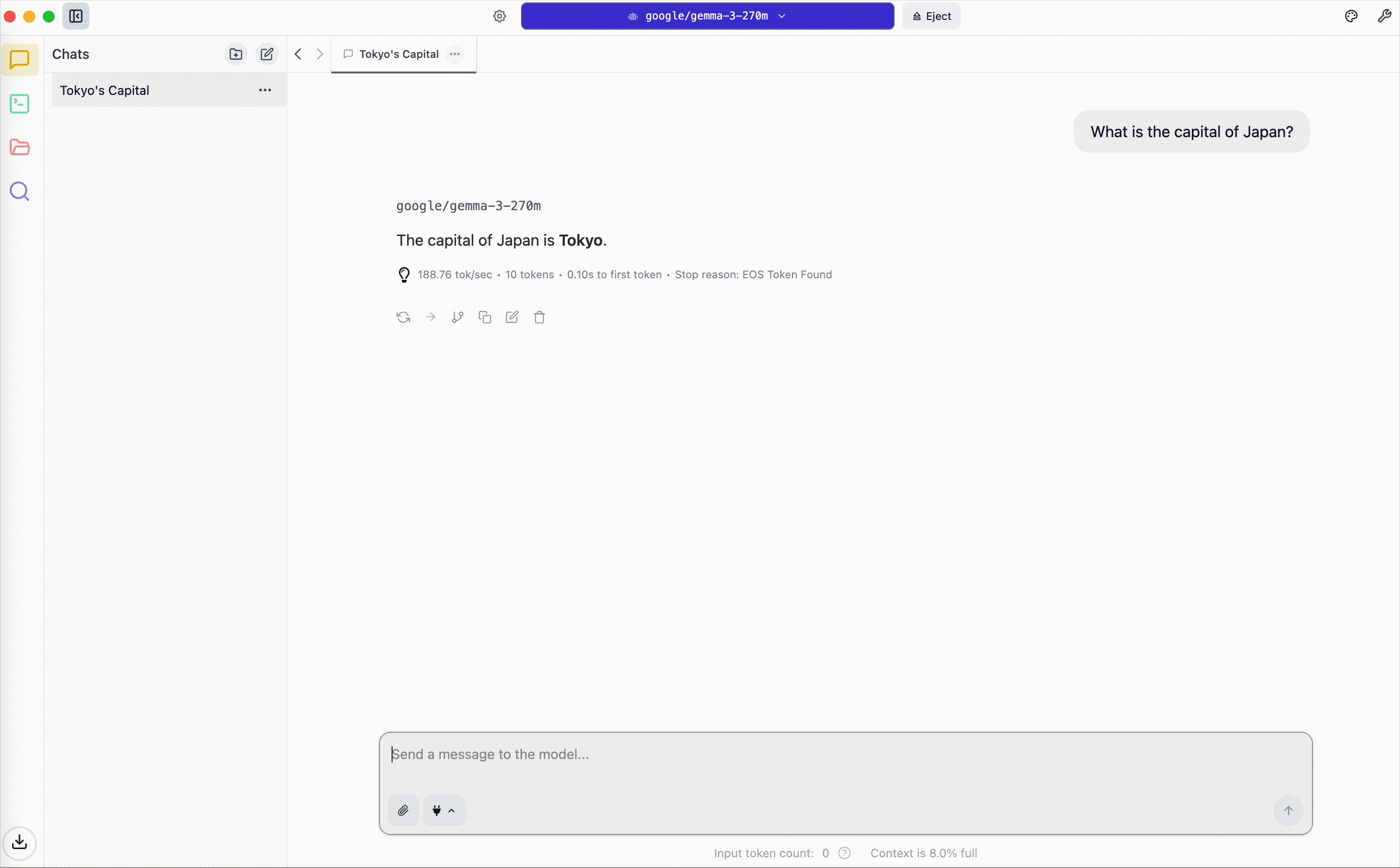
まずは日本の首都を聞いてみます。

私が利用しているPC が2023年のMacBookProですが、非常に高速に動作することが分かります。
一方で、回答のニュアンス的には正解であるものの、日本語の文法自体はかなり怪しいということも分かります。
多言語対応などの性能がそこまで優れていない可能性もあるため、次は英語で簡単な質問を投げてみます。
日本語と異なり英語であれば、あくまで簡単な文法ではあるものの、適切な文法で回答を返してくれることが分かりました。
「ChatGPT について教えてください」という、より実践的な汎用的なチャットとしての会話を試みます。
まずは英語で ChatGPT に関する説明を依頼します。
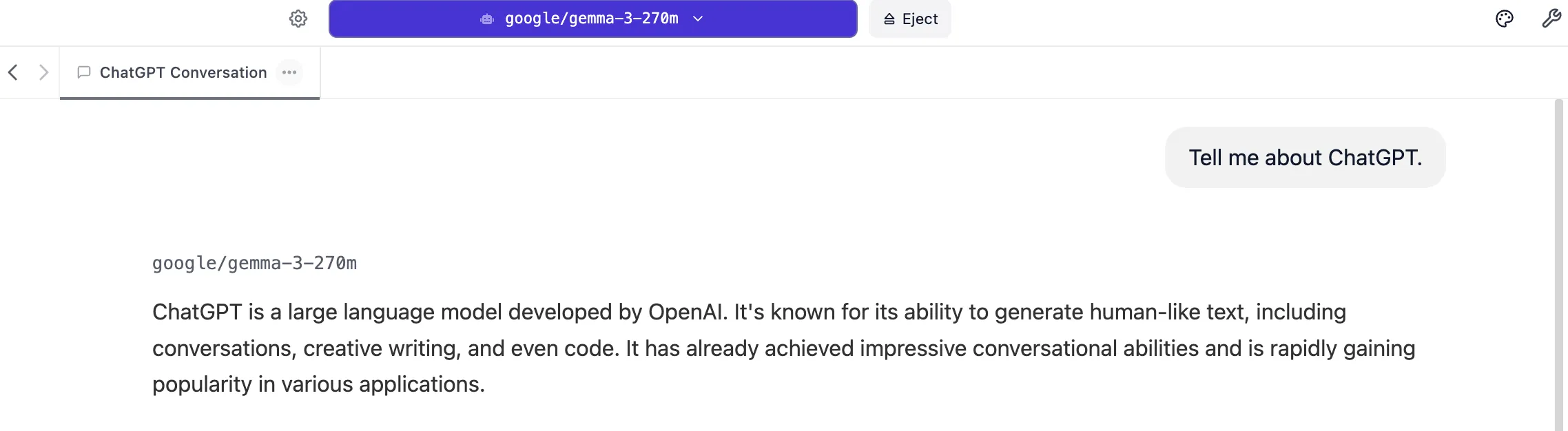
それなりに適当な答えが得られました。
次に日本語で説明を依頼します。
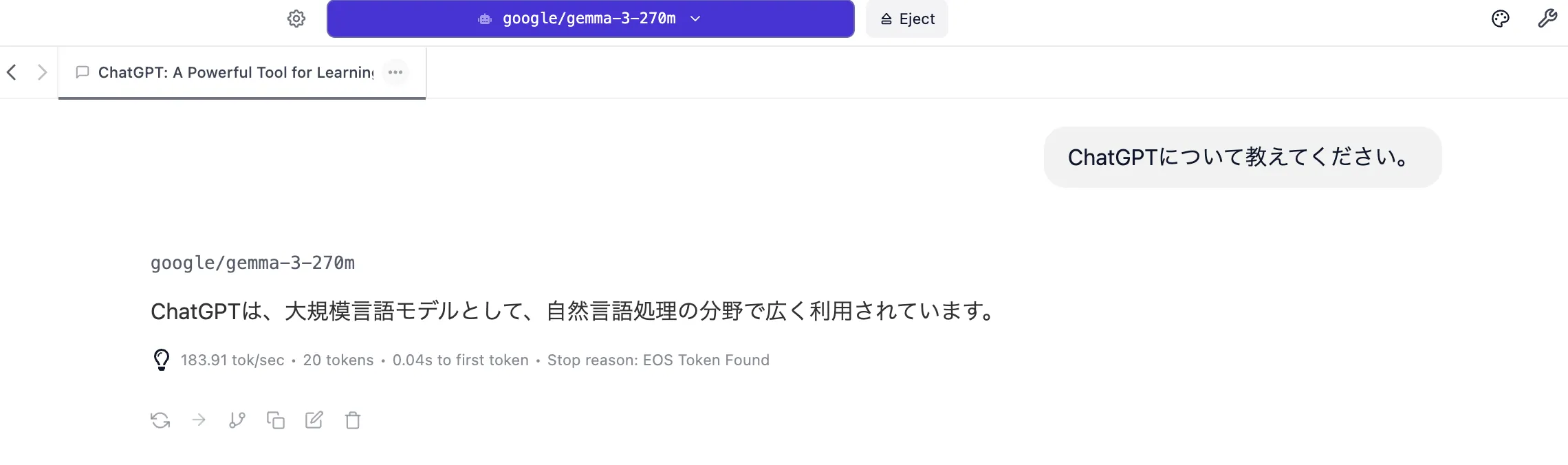
どうしても英語と比較するとあまりに簡潔すぎる回答のような感覚があります。
これまでのポイントを加味すると、
という使い道が良いのではないかと考えられます。
Googleの最新軽量LLM「Gemma 3 270M」は、そのコンパクトな構成と実用性の高さから、ローカル環境でのAI活用に大きな可能性をもたらしています。
特に、LM Studio のようなユーザーフレンドリーなツールを使えば、専門的な知識がなくても比較的簡単にモデルを動かすことができます。
軽量であることの強みは、次のような場面で特に発揮されます。
もちろん、Gemma 3 270M は GPT-5 や Gemini 2.5 のような大規模モデルと比べると汎用性では劣る部分があります。しかしその代わり、明確な目的に応じた使い方をすれば、非常に高いパフォーマンスを発揮できるモデルです。
今後、個人や中小規模の開発者がAIを使ったプロダクトを迅速に構築する際の、有力な選択肢の一つになるでしょう。
株式会社Digeonでは、「Gemma 3」「gpt-oss」「Llama」などのLLMを、自社専用の安全な環境で活用したいお客様のために、 ローカルLLM構築サービス を提供しています。
ISMS認証取得企業によるセキュアな設計と、RAGやOCR、多言語対応などの豊富な機能を備えたAI活用基盤を、貴社の環境に合わせて構築します。
まず話を聞いてみたいという方は、以下のページからお問い合わせください。
またディジョンは、法人向けに ChatGPT をセキュアに使えるサービスである「ENSOUチャットボット」を提供しています。
サービス紹介資料をこちらからダウンロードいただけます👇
https://ensou.app/downloads/chatbot_overview/
お打ち合わせやトライアルなど、製品へのお問い合わせはこちらから👇
著者
 山﨑 祐太
山﨑 祐太 山﨑 祐太
山﨑 祐太 山﨑 祐太
山﨑 祐太 山﨑 祐太
山﨑 祐太 山﨑 祐太
山﨑 祐太 山﨑 祐太
山﨑 祐太