

目次
2025年9月4日、Googleはデバイス向けに特化した高速に動作する埋め込みモデルである 「EmbeddingGemma」をオープンソースモデルとしてリリース しました。
308Mのパラメータ数で構成された EmbeddingGemma は、優れたパフォーマンスを実現しながら、デバイス上でインターネット接続なしでも動作するように設計されたモデルです。
本記事ではそんな EmbeddingGemma について徹底解説していきます。
関連記事として、2025年8月に同じく Googleが発表した軽量LLMの Gemma 3 270M の解説記事 を公開しています。よろしければこちらも併せてご覧ください。
EmbeddingGemma は、3億800万のパラメータをもつオープンな埋め込みモデルです。
埋め込みモデルはいわゆるLLMとは異なり、テキストをベクトルに変換する処理を行うモデルであり、RAGやセマンティック検索などで用いられます。
100以上の言語で学習されており多言語の埋め込みが可能であり、また量子化処理により200MB未満のRAMで実行できるほど小型です。
EmbeddingGemma は、308Mのパラメータ数を持ち、約1億個のモデルのパラメータ、約2億個の埋め込みパラメータから構成されています。
この EmbeddingGemma の特徴は、小型・高速であり、デバイス上で動作するように設計されたモデルであることです。
特に携帯電話・ノートパソコン・デスクトップパソコンなどでの利用を想定されており、高価なGPUサーバーやその上でホストされたAPIを利用することなく、インターネット通信なしで軽量かつ高精度で動作するようなユースケースのために開発されました。
またデバイス用の設計として、複数サイズのテキスト埋め込みが可能であり、最大768次元のベクトル化の他に、128、256、512のサイズのベクトルへ埋め込むことができ、そのデバイスに合わせた最適なベクトルの次元数でアプリケーションを構築できます。
Massive Text Embedding Benchmark において、500M以下のパラメータ数のオープンな多言語埋め込みモデルとの比較で、最高のパフォーマンスを発揮することが示されました。
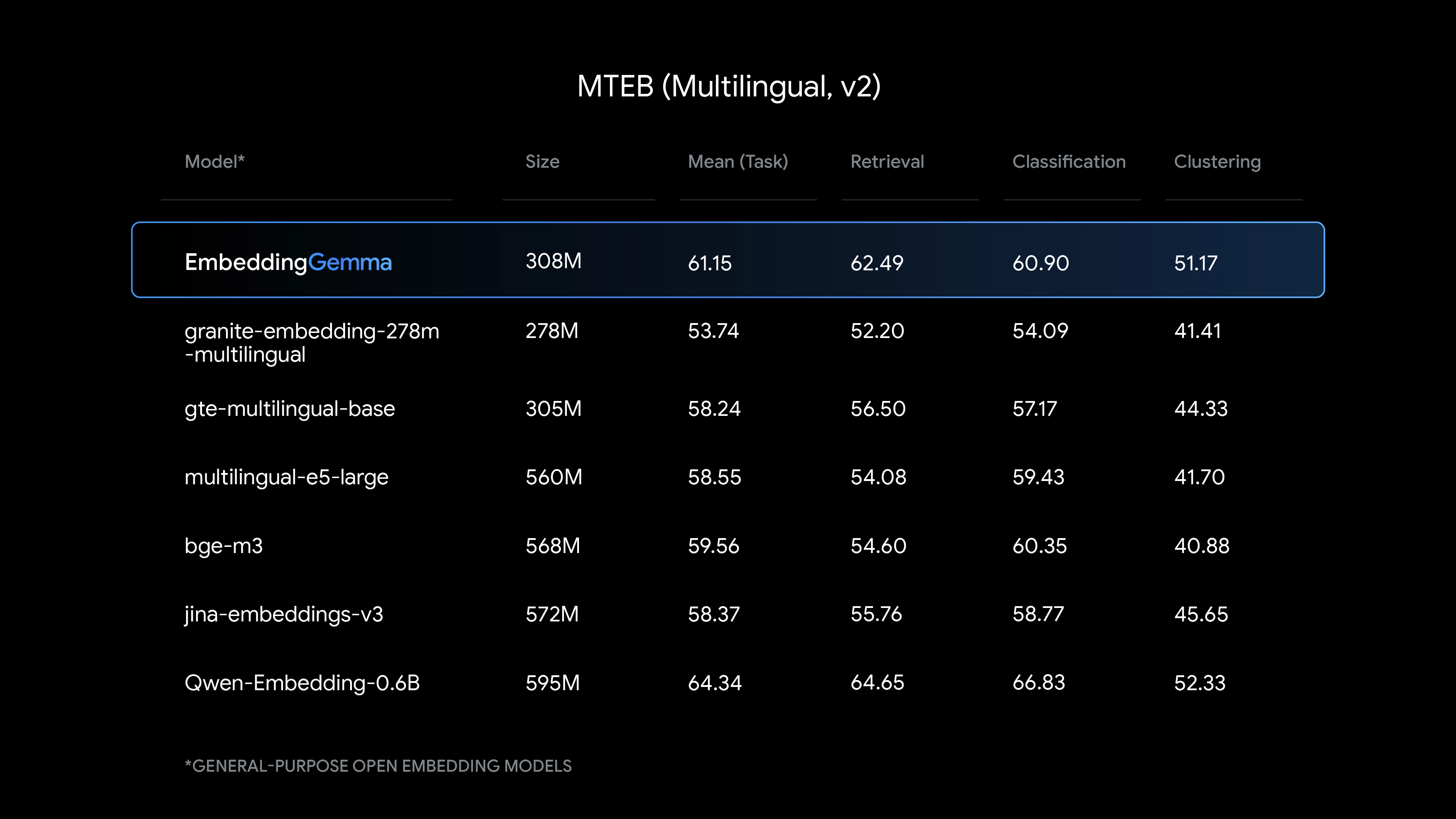
同様のサイズのオープンな多言語埋め込みモデルと比較して、
などのタスクにおいて、最も高いパフォーマンスを示しています。
上記の表内で記載されている Qwen-Embedding-0.6B は EmbeddingGemma の約2倍のパラメータ数を有しており、この2倍のパラメータを持つモデルに比肩するパフォーマンスを発揮していることが分かります。
ここでは LM Studio でローカルのEmbedding取得用のAPIを立てて、curlでEmbddingGemmaによる埋め込み結果を受け取る例を示します。
LM Studio をダウンロード、そしてインストールします。
LM Studio で利用可能な EmbeddingGemma のモデルは以下のURLで提供されています。
https://lmstudio.ai/models/google/embedding-gemma-300m
上記URLの画面を開き、「Use Model in LM Studio」をクリックします。
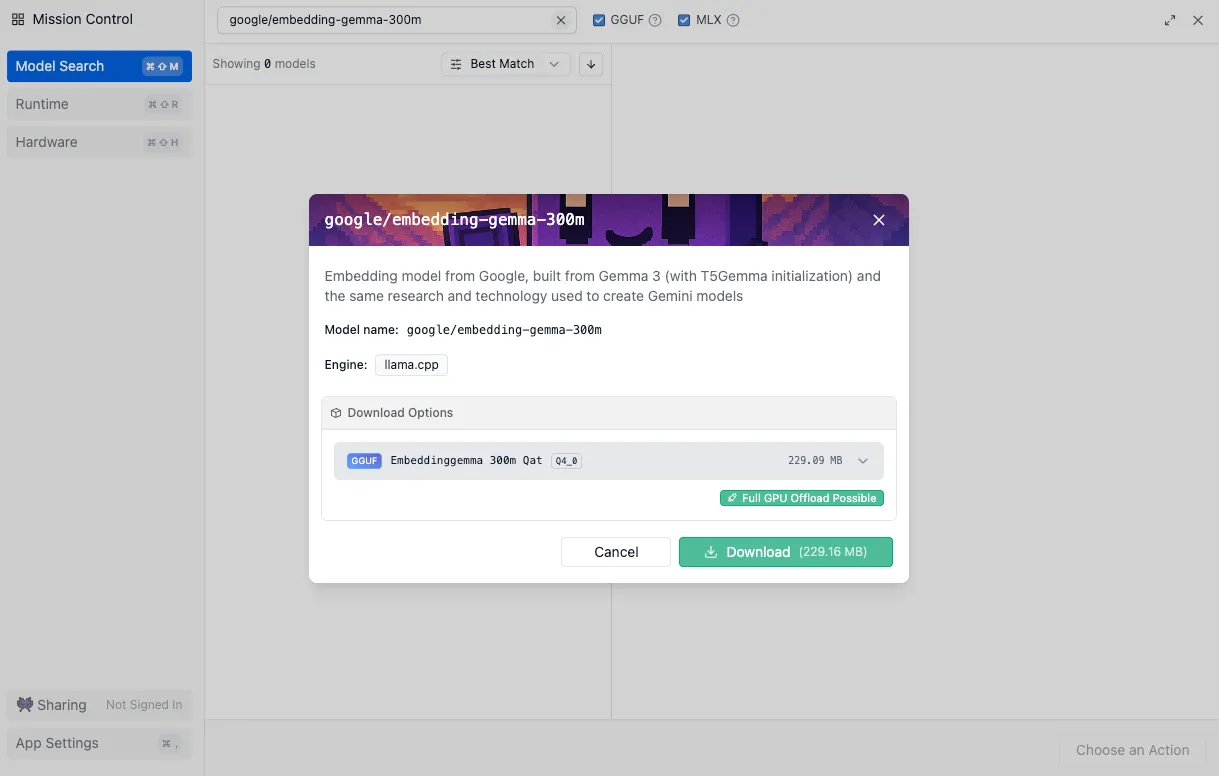
すると LM Studio の画面が開きますので、「Download」を押下し、モデルのダウンロードを実行ます。モデルサイズは229.16MBと非常に軽量な埋め込みモデルであることが分かります。
ダウンロード完了後はアプリ上部にある「Select a model to load」から、「Embedding Gemma 300m」を選択します。

モデルのロードが完了し、LM Studio のサーバーをローカルで実行します。すると、 http://localhost:1234/v1/embeddings から、埋め込みを取得するためのAPIリクエストを実行できるようになります。
今回は以下のようなリクエストを送信し、「こんにちは」というテキストの分散表現を取得してみます。
curl http://127.0.0.1:1234/api/v0/embeddings \
-H "Content-Type: application/json" \
-d '{
"model": "google/embedding-gemma-300m",
"input": "こんにちは"
}'上記を実行すると以下のようなレスポンスを受け取ることができます。
{
"object": "list",
"data": [
{
"object": "embedding",
"embedding": [
0.046109940856695175,
0.012861200608313084,
-0.025736985728144646,
0.06820180267095566,
...
-0.02455161139369011
],
"index": 0
}
],
"model": "google/embedding-gemma-300m",
"usage": {
"prompt_tokens": 0,
"total_tokens": 0
}
}この分散表現を利用してベクトル検索を実現することによって、RAGアプリの構築など様々なタスクに活用できます。
また LM Studio のAPIは OpenAI API 互換で作られているため、各種OpenAI SDKを利用することで、簡単にRAGアプリなどの構築が可能です。
EmbeddingGemma は、Googleが開発した非常に軽量かつ高性能な埋め込みモデルです。
特筆すべきは、約200MBという小さなサイズながら、500M未満の同カテゴリのモデル群を凌ぐパフォーマンスを発揮している点です。
デバイス上での利用を前提に設計されており、インターネットに接続せずに高速なベクトル変換処理が行えることから、セキュアなRAG構築やオフライン対応のアプリ開発に最適な選択肢となります。
また、LM Studioとの連携により、OpenAI互換のAPIで簡単に利用できる点も大きなメリットです。
今後、オンデバイスAIの需要が高まる中で、EmbeddingGemmaはその中心的存在となる可能性を秘めています。
株式会社Digeonでは、「Gemma 3」「gpt-oss」「Llama」などのLLMを、自社専用の安全な環境で活用したいお客様のために、 ローカルLLM構築サービス を提供しています。
ISMS認証取得企業によるセキュアな設計と、RAGやOCR、多言語対応などの豊富な機能を備えたAI活用基盤を、貴社の環境に合わせて構築します。
まず話を聞いてみたいという方は、以下のページからお問い合わせください。
またディジョンは、法人向けに ChatGPT をセキュアに使えるサービスである「ENSOUチャットボット」を提供しています。
サービス紹介資料をこちらからダウンロードいただけます👇
著者
 山﨑 祐太
山﨑 祐太 山﨑 祐太
山﨑 祐太 山﨑 祐太山﨑 祐太
山﨑 祐太山﨑 祐太 山﨑 祐太
山﨑 祐太 山﨑 祐太
山﨑 祐太