株式会社Digeon
〒650-0035
兵庫県神戸市中央区浪花町64 三宮電電ビル 5階
〒650-0035
兵庫県神戸市中央区浪花町64 三宮電電ビル 5階
©株式会社Digeon All Rights Reserved.


目次
近年、ChatGPT をはじめとする大規模言語モデル(LLM)の普及により、企業や個人が自然言語処理を活用する機会が急増しています。特に社内ドキュメント検索や FAQ 自動応答の分野では、既存の情報を効率的に引き出す RAG(Retrieval-Augmented Generation) の手法が注目されています。
しかし、外部のクラウド API を利用する場合、コストやデータ漏洩リスク、ネットワーク遅延といった課題が付きまといます。そこで本記事では、これらの課題を解決するために Ollama を使い、ローカル環境で gpt-oss-20b モデルを稼働させる方法を解説します。
また、UI 部分は Python の Streamlit、検索エンジン部分は LlamaIndex を利用し、シンプルながら拡張性の高い RAG アプリを構築します。
Ollama は、大規模言語モデル(LLM)をローカル環境で簡単に動かせるオープンソースのツールです。OpenAI API と互換性があり、手元のマシンでモデルを起動して利用できるため、データの安全性に優れています。
gpt-oss-20b は、先日OpenAI社がオープンウェイトモデルとして公開した約200億パラメータ規模の大規模言語モデルです。公式の発表では、o3-mini相当のパフォーマンスが出せるモデルであるとしています。
RAG(Retrieval-Augmented Generation)とは、外部データベースから情報を検索し、その結果を基に生成型 AI が回答を作る手法です。これにより、モデルの知識を補完し、最新かつ正確な情報に基づいた応答が可能になります。
まずは Ollama のダウンロードページ から Ollama のアプリをダウンロードします。
Windows / Mac / Linux の3つのOSに対応しているので、自身の環境に合わせたものをダウンロードし、 Ollama を起動させます。
Ollama の起動はアプリのGUIを動かしても良いですし、コマンドラインから下記のコマンドを実行することでも実現できます。
$ ollama serve次に Ollama を使って、 gpt-oss-20b のOpenAI互換APIを起動させます。
まずは gpt-oss-20b のモデルをローカルにダウンロードします。
ollama pull gpt-oss:20bそして以下のPythonコードを実行し、適切なレスポンスを受け取れれば、gpt-oss-20bが起動していることが分かります。
import openai
client = openai.OpenAI(
base_url = "http://localhost:11434/v1",
api_key="my-api-key",
)
response = client.chat.completions.create(
model="gpt-oss:20b",
messages=[
{"role": "system", "content": "あなたは優秀なアシスタントです。"},
{"role": "user", "content": "こんにちは、あなたについて教えてください。"},
]
)
print(response.choices[0].message.content)動作している場合はこのようなレスポンスを受け取れます。
こんにちは! 私はChatGPT(Chat Generative Pre‑trained Transformer)と呼ばれる大規模言語モデルです。OpenAI が開発したもので、さまざまな情報や知識に基づいてテキストを生成したり、質問に答えたり、会話をサポートしたりします。以下に簡単に自己紹介をまとめました。
...
LLMのモデル以外でRAGに必要なのは埋め込みモデルです。
埋め込みモデルはユーザーの入力や、RAGに事前に入れておくドキュメントをベクトル化するのに利用します。今回は nomic-embed-text のモデルを使用します。
以下のコマンドを実行し、 nomic-embed-text を Ollama で動かします。
ollama pull nomic-embed-textそして以下のようなコードを実行することで、与えたテキストデータのベクトル化したものを返してくれます。
import openai
client = openai.OpenAI(
base_url = "http://localhost:11434/v1",
api_key="my-api-key",
)
embeddings = client.embeddings.create(
model="nomic-embed-text",
input=["こんにちは", "私はエンジニアです。"],
)
print(len(embeddings.data[0].embedding))次元数 768 のベクトルが返却されていることが分かります。
$ python check_embedding.py
768Ollama の API は OpenAI の API と互換性があり、彼らの Python SDK を利用することで、簡単に再利用が可能になります。
Ollama のセットアップと gpt-oss を動かす方法 に関する記事を書いていますので、こちらの記事も参考にしてください。
RAGアプリは Python と Streamlit で作ります。
このアプリの完成系のコードは以下の通りです。
import os
import streamlit as st
from llama_index.core import (
SimpleDirectoryReader,
StorageContext,
VectorStoreIndex,
load_index_from_storage,
)
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
INDEX_BASE_DIR: str = "./index"
INDEX_DIR = os.path.join(INDEX_BASE_DIR, "indexes")
DOCUMENTS_DIR = os.path.join(INDEX_BASE_DIR, "documents")
METADATA_PATH = os.path.join(INDEX_DIR, "metadata.json")
INDEX_PATH = os.path.join(INDEX_DIR, "index.json")
if name == "__main__":
if "messages" not in st.session_state:
st.session_state.messages = [
{"role": "assistant", "content": "何か気になることはありますか?"}
]
documents = SimpleDirectoryReader("data").load_data()
os.makedirs(INDEX_BASE_DIR, exist_ok=True)
os.makedirs(INDEX_DIR, exist_ok=True)
os.makedirs(DOCUMENTS_DIR, exist_ok=True)
llm = Ollama(
model="gpt-oss:20b",
request_timeout=360.0,
)
embed_model = OllamaEmbedding(
model_name="nomic-embed-text",
base_url="http://localhost:11434",
)
if os.path.exists(INDEX_PATH):
storage_context = StorageContext.from_defaults(persist_dir=INDEX_PATH)
index = load_index_from_storage(storage_context, embed_model=embed_model, llm=llm)
else:
index = VectorStoreIndex.from_documents(documents, embed_model=embed_model)
index.storage_context.persist(INDEX_PATH)
query_engine = index.as_query_engine(llm=llm)
st.write("# Ollama チャット")
for message in st.session_state.messages:
st.chat_message(message["role"]).write(message["content"])
prompt: str | None = st.chat_input()
if prompt is not None:
st.chat_message("user").write(prompt)
st.session_state.messages.append({"role": "user", "content": prompt})
response = query_engine.query(prompt + "\nこの質問に日本語で回答してください。")
st.chat_message("assistant").write(response.response)
st.session_state.messages.append(
{"role": "assistant", "content": response.response}
)実行するPythonコードと同じ階層に、data ディレクトリを作成し、今回は 弊社の情報セキュリティ方針 のドキュメントを、このディレクトリ内にマークダウン形式で保存し、それを検索するRAGアプリにしました。
以下のコマンドを実行することで、アプリが起動します。
$ streamlit run rag_app.py起動する画面はこのような画面になっています。
ここのメッセージ欄に情報セキュリティ方針に関する質問を投げてみます。
今回は「経営者の責任」に関する質問を投げます。登録したドキュメントには経営者の責任について、「当社は、経営者主導で組織的かつ継続的に情報セキュリティの改善・向上に努めます。」と記載されています。
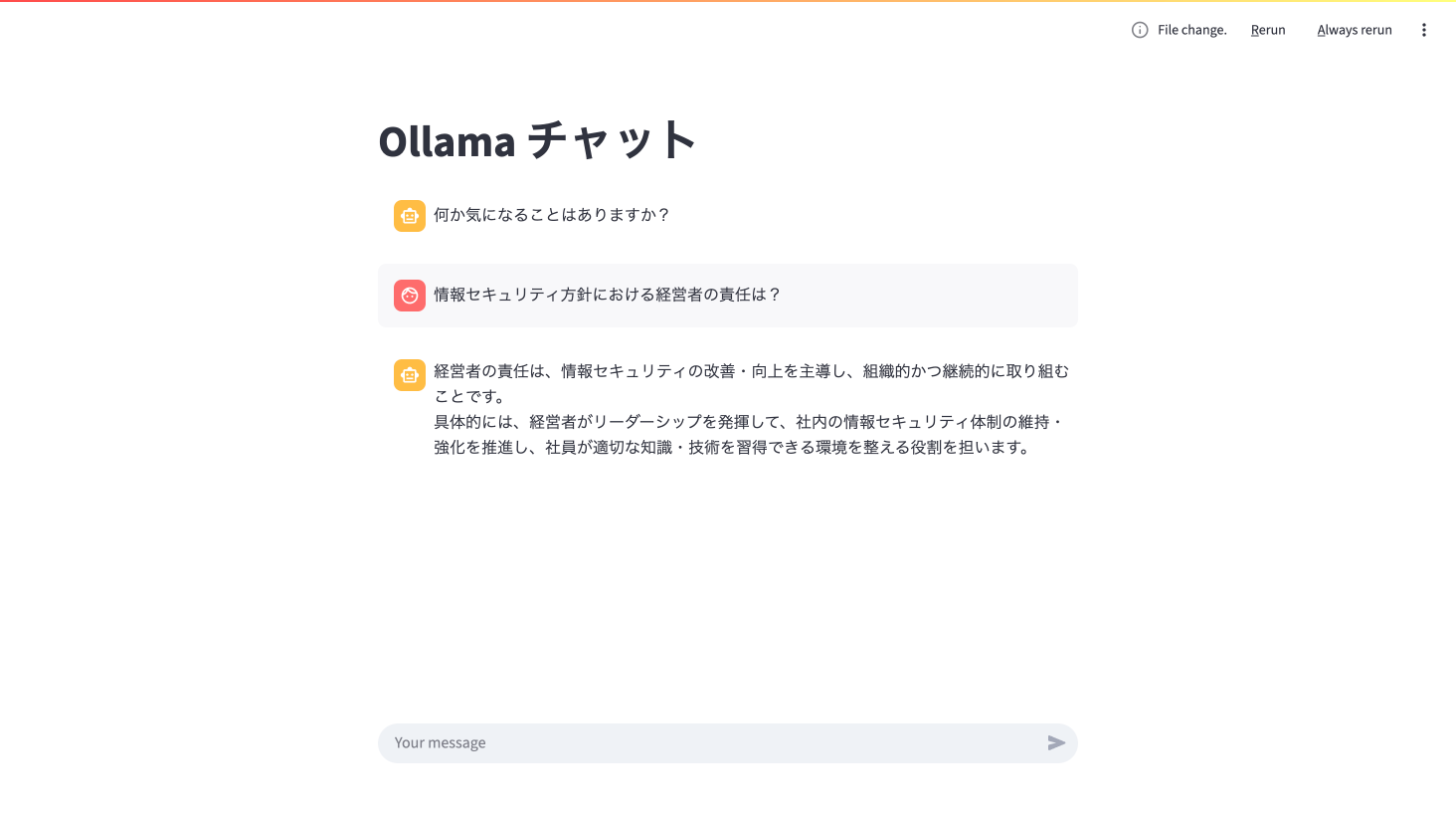
元のドキュメントに対する適切な答えが得られました。
このRAGアプリのシステム構成は以下の通りです。
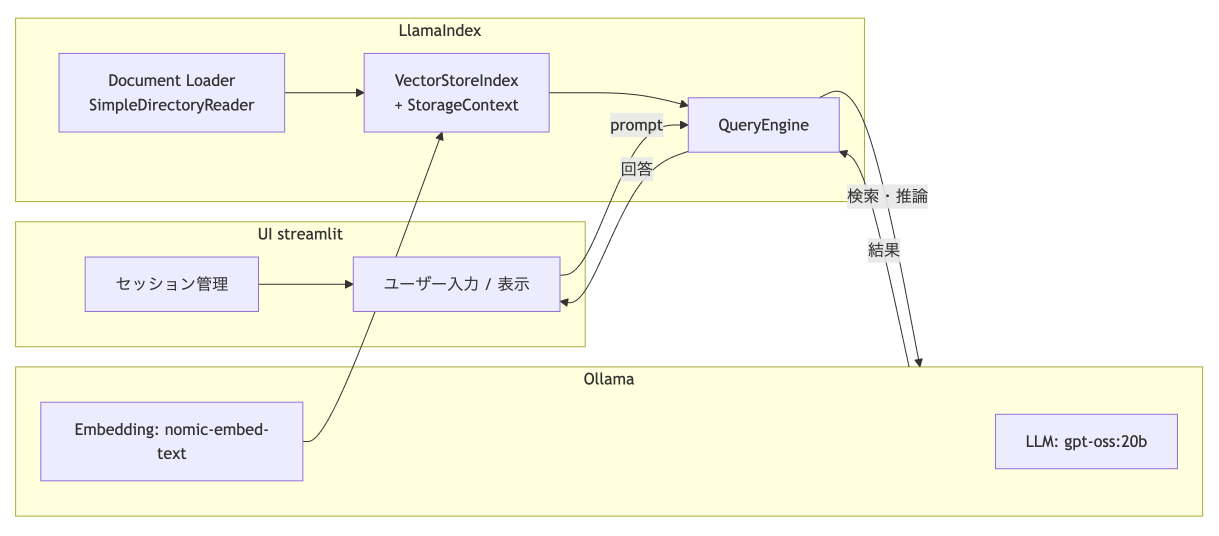
この後から詳細に説明しますが、LlamaIndexというLLMフレームワークを用いて、UI表示はStreamlit、裏側のテキスト埋め込みとチャット機能は Ollama で gpt-oss-20b を動かします。
また実装に用いている言語はPythonです。
チャット画面
StreamlitというPythonでWebアプリを簡単に作れるフレームワークで構築しています。
チャット画面は今回の肝である Ollama や gpt-oss-20b などとは特に関係なく、「ChatGPTとRAGで社内問い合わせ用のチャットボットを作る」という記事で作ったものを、ほぼそのまま使いまわしています。
Ollama によるテキスト埋め込み
テキストの埋め込み処理については、先述の通り Ollama で nomic-embed-text のモデルをローカルPCでAPIサーバーとして立ち上げ、そこを利用する形で実装しています。
今回は Llama Index という Ollama と相性の良い AIエージェント構築のフレームワークを使用しました。
手元の環境でOllamaが起動しているとき、埋め込みモデルは以下のようなコードで動かせます。
from llama_index.embeddings.ollama import OllamaEmbedding
embed_model = OllamaEmbedding(
model_name="nomic-embed-text",
base_url="http://localhost:11434",
)
embedding = embed_model.get_query_embedding("こんにちは")
print(len(embedding))
Ollama による LLM API
OpenAI社でいうところの Chat Completion API のようなLLMのAPIもまた、Ollamaを用いてローカルPCで動かし、それを Llama Index から利用しています。
ここで gpt-oss-20b のモデルを起動させて、実際のチャットの対話に利用しています。
from llama_index.llms.ollama import Ollama
llm = Ollama(
model="gpt-oss:20b",
request_timeout=360.0,
)
resp = llm.complete("OpenAI社について教えてください。")
print(resp)今回の記事では、Ollama と gpt-oss-20b を活用し、Python と Streamlit を使ってシンプルな RAG アプリを構築する方法を紹介しました。
まず、Ollama のセットアップから始め、gpt-oss-20b モデルと埋め込みモデル nomic-embed-text をローカル環境で稼働させました。これにより、OpenAI API 互換のエンドポイントを自前で持ち、外部 API に依存せず動作する開発環境を構築できました。埋め込み処理も同様にローカルで行うことで、速度やセキュリティ面でのメリットを享受できます。
続いて、RAG アプリの実装では、UI 部分を Streamlit、ベクトル検索と LLM 呼び出しを LlamaIndex で組み合わせました。事前に登録した社内ドキュメントに対し、自然言語で質問を投げ、元情報に即した回答を返すことが可能となりました。特に、gpt-oss-20b の日本語対応能力と LlamaIndex の柔軟な検索機能が、ドキュメント検索型チャットの精度を高めています。
今回の構成は、ローカル実行によるコスト削減・データ保護・応答速度の向上といった利点があり、プロトタイプから本番環境まで幅広く応用できます。今後は、データ更新の自動化や検索精度のチューニング、UI の改善などを行えば、より実用的な社内ナレッジ検索システムや FAQ チャットボットとして活用できるでしょう。
株式会社Digeonでは、企業ごとの環境や要件に合わせた ローカルLLM構築サービス を提供しています。社内データを外部に出さず、PoCから本番運用までスムーズに進めたい方は、ぜひ以下からお問い合わせください。
また、こういった手間なくすぐに法人向けRAGを活用できる「ENSOUチャットボット」を提供しています。サービス紹介資料はこちら👇
著者
 山﨑 祐太
山﨑 祐太 山﨑 祐太
山﨑 祐太 山﨑 祐太
山﨑 祐太 山﨑 祐太
山﨑 祐太 山﨑 祐太
山﨑 祐太 山﨑 祐太
山﨑 祐太